<- See more new Stata features
Highlights
H2O machine learning using ensemble decision trees
Methods: Gradient boosting machine (GBM) and random forest
Regression, binary classification, and multiclass classification
Hyperparameter tuning, model performance, and prediction
Cross-validation (CV) and grid-search summary
Prediction explainability
Variable importance
Partial dependence plot (PDP)
Shapley additive explanations (SHAP) importance and beeswarm plots
See more H2O machine learning features
With the new h2oml suite, use machine learning via H2O to uncover insights from data when traditional statistical models fall short. Use ensemble decision trees—gradient boosting machine (GBM) or random forest—to perform classification or regression. Tune hyperparameters, use validation or cross-validation (CV), evaluate model performance, explain predictions, and more. These features are part of StataNow™.
Stata users have long relied on linear regression, logistic regression, and traditional statistical models to uncover insights from their data. There are many applications, where relationships are often complex and nonlinear, and these classical methods may fall short in capturing more intricate data patterns.
This is where GBMs and random forests revolutionize the way you analyze your data in Stata. With seamless access to H2O's machine learning algorithms from within Stata, you can now harness the power of high-performance predictive models without leaving your familiar Stata environment. Simply use commands with intuitive Stata syntax to train sophisticated ensemble learning models that outperform traditional techniques. Think machine learning is a “black box”? Not anymore! With tools such as Shapley additive explanations (SHAP) values, partial dependence plots (PDPs), and variable importance rankings, GBM and random forest provide powerful predictions while maintaining explainability—no tradeoffs needed.
Let's quickly look at one possible workflow below. Also see the summary of all commands and features in Commands for Stata integration with H2O machine learning and more examples in Let's see it work.
1. Setup and data preparation
Initialize an H2O cluster, and import your current Stata dataset into an H2O frame named data:
. h2o init . _h2oframe put, into(data) current
Split data into the training (80%) and validation (20%) sets:
. _h2oframe split data, into(train valid) split(0.8 0.2) rseed(19) . _h2oframe change train
2. Reference (baseline) model
Fit a GBM model to a binary response using default hyperparameters:
. h2oml gbbinclass response predictors, h2orseed(19) validframe(valid)
Or use 3-fold CV instead of a validation set:
. h2oml gbbinclass response predictors, h2orseed(19) cv(3)
Store the reference (baseline) model:
. h2omlest store gbm_ref
3. User-specified hyperparameters and tuning
Specify different values for any of the 11 hyperparameters. For example, specify 200 trees and a learning rate of 0.2:
. h2oml gbbinclass response predictors, h2orseed(19) cv(3) ntrees(200) lrate(0.2)
Store the model with user-specified hyperparameters:
. h2omlest store gbm_user
Perform hyperparameter tuning on the number of trees and learning rate:
. h2oml gbbinclass response predictors, h2orseed(19) cv(3) ntrees(20(10)200) lrate(0.1(0.1)1)
Store the best-tuned model:
. h2omlest store gbm_tuned
Customize tuning settings by specifying accuracy as the tuning metric, and perform a random grid-search method:
. h2oml gbbinclass response predictors, h2orseed(19) cv(3) ntrees(20(10)200) lrate(0.1(0.1)1)
tune(metric(accuracy) grid(random))
4. Evaluate model performance
Check for overfitting or underfitting using score history plots:
. h2omlgraph scorehistory
Assess CV performance:
. h2omlestat cvsummary
View grid summary for configurations of hyperparameters ranked by model performance:
. h2omlestat gridsummary
Compare the top 10 models using various metrics:
. h2omlexplore id = 1(1)10
Manually select a specific model:
. h2omlselect id = #
Evaluate model metrics:
. h2omlestat metrics . h2omlgof gbm_tuned gbm_user gbm_ref
5. Compare different methods
Suppose you have repeated steps 2 through 4 to select the best random forest model rf_tuned. You may compare the GBM model gbm_tuned with the random forest model rf_tuned as follows:
. h2omlgof gbm_tuned rf_tuned . h2omlgraph prcurve, models(gbm_tuned rf_tuned) . h2omlgraph roc, models(gbm_tuned rf_tuned)
6. Make predictions
Use the best model to make predictions:
. h2omlest restore gbm_tuned . _h2oframe change data . h2omlpredict
7. Explain model results
Assess variable importance:
. h2omlgraph varimp
Produce PDP and an individual conditional expectation (ICE) plot:
. h2omlgraph pdp predictors . h2omlgraph ice predictor
Analyze SHAP values for predictor contributions:
. h2omlgraph shapvalues . h2omlgraph shapsummary
| h2oml gbregress | Gradient boosting regression |
|---|---|
| h2oml gbbinclass | Gradient boosting binary classification |
| h2oml gbmulticlass | Gradient boosting multiclass classification |
| h2oml rfregress | Random forest regression |
| h2oml rfbinclass | Random forest binary classification |
| h2oml rfmulticlass | Random forest multiclass classification |
| h2omlest | Catalog H2O estimation results |
|---|---|
| h2omlpostestframe | Specify frame for postestimation analysis |
| h2omlestat metrics | Display performance metrics |
|---|---|
| h2omlgof | Goodness of fit for machine learning methods |
| h2omlestat cvsummary | Display CV summary |
| h2omlestat gridsummary | Display grid-search summary |
| h2omlexplore | Explore models after grid search |
| h2omlselect | Select model after grid search |
| h2omlgraph scorehistory | Produce score history plot |
| h2omlestat threshmetric | Display threshold-based metrics |
|---|---|
| h2omlestat confmatrix | Display confusion matrix |
| h2omlgraph prcurve | Produce precision–recall curve plot |
| h2omlgraph roc | Produce receiver operating characteristic (ROC) curve plot |
| h2omlpredict | Prediction of continuous responses, probabilities, and classes |
|---|
| h2omlgraph varimp | Produce variable importance plot |
|---|---|
| h2omlgraph pdp | Produce partial dependence plot |
| h2omlgraph ice | Produce individual conditional expectation plot |
| h2omlgraph shapvalues | Produce SHAP values plot for individual observations |
| h2omlgraph shapsummary | Produce SHAP beeswarm plot |
| h2omltree | Save decision tree DOT file and display rule set |
|---|
-> Example dataset: Telco customer churn dataset
-> Prepare your data for H2O machine learning in Stata
-> Reference GBM model
-> Model selection and hyperparameter tuning
-> Method selection: GBM versus random forest
-> Prediction on new data
-> Explaining predictions
-> Global explainability methods
-> Local explainability methods
-> Shutting down the H2O cluster
To demonstrate the h2oml suite, we focus on a GBM for binary classification model. Other models such as random forest or GBM for regression have similar syntax and workflow. We'll analyze data from a fictional telecommunications company called Telco that offers home phone and Internet services in California. The dataset, provided by IBM, contains information on 7,043 customers with 26 variables. Our main objective is to develop a predictive model that can identify which customers are at risk of churning—meaning they might terminate their services with Telco. Our binary response, churn, indicates whether a customer discontinued service in the past month or remained with Telco.
The predictors (features) include customer demographics (such as gender and age); account details (such as contract type and tenure length); and service subscriptions (such as Internet, phone, and security service).
We want to predict customer behavior patterns that signal potential churn, which could help Telco take proactive steps to retain valuable customers.
We first load our dataset and initiate an H2O cluster.
. webuse churn.dta . h2o init
We then put the current dataset into an H2O frame, churn, and make it the current H2O frame.
. _h2oframe put, into(churn) current
We split our data into training and testing frames with 80% of observations in the training sample. Later on, we will use CV on training data during estimation to control for overfitting.
. _h2oframe split churn, into(train test) split(0.8 0.2) rseed(19) . _h2oframe change train
For convenience, we create a global macro to store the names of predictors.
. global predictors latitude longitude tenuremonths monthlycharges totalcharges gender seniorcitizen
partner dependents phoneservice multiplelines internetserv onlinesecurity onlinebackup streamtv
techsupport streammovie contract paperlessbill paymethod deviceprotect
We fit a GBM model with 3-fold stratified CV (SCV) using default values for other settings and h2orseed(19) for reproducibility. SCV is particularly useful for classification tasks with imbalanced classes (levels of churn).
. h2oml gbbinclass churn $predictors, h2orseed(19) cv(3, stratify)
Progress (%): 0 7.9 55.0 88.4 100
Gradient boosting binary classification using H2O
Response: churn
Loss: Bernoulli
Frame: Number of observations:
Training: train Training = 5,643
Cross-validation = 5,643
Cross-validation: Stratify Number of folds = 3
Model parameters
Number of trees = 50 Learning rate = .1
actual = 50 Learning rate decay = 1
Tree depth: Pred. sampling rate = 1
Input max = 5 Sampling rate = 1
min = 5 No. of bins cat. = 1,024
avg = 5.0 No. of bins root = 1,024
max = 5 No. of bins cont. = 20
Min. obs. leaf split = 10 Min. split thresh. = .00001
Metric summary
| Cross- | ||
| Metric | Training validation | |
| Log loss | .3293387 .411338 | |
| Mean class error | .1592684 .2338787 | |
| AUC | .9163462 .8500772 | |
| AUCPR | .8024264 .6584908 | |
| Gini coefficient | .8326924 .7001545 | |
| MSE | .1034999 .1350446 | |
| RMSE | .321714 .3674841 | |
The header provides model details, showing that h2oml gbbinclass uses Bernoulli loss (other loss functions are available for regression with h2oml gbregress). The training frame contains 5,643 observations, and 3-fold SCV on training data is used. The hyperparameters section (Model parameters) reports both user-specified and actual values for hyperparameters, which may differ if early stopping is specified.
The metric summary table presents binary classification performance metrics for the training and CV data. We will rely on the area under the precision–recall curve (AUCPR) as the metric of choice because we have imbalanced classes. AUCPR ranges from 0 to 1, with 1 meaning perfect performance. While CV metrics are our main focus, we also check training metrics to ensure slight overfitting and to avoid underfitting. The positive difference between training and CV AUCPR (0.8024 - 0.6585 = 0.1439) is expected, but a large gap may suggest overfitting, meaning the model may not generalize well to new data.
We store the reference estimation results for later comparison:
. h2omlest store gbm_default
Assessing metric variability across the three folds ensures model performance is not tied to a specific data split. High variation in CV metrics may indicate poor generalization to new data. This can be done by using the h2omlestat cvsummary command; see example 2 of [H2OML] h2oml and [H2OML] h2omestat cvsummary.
Our baseline model's CV AUCPR was 0.6585. To improve model performance, we will tune hyperparameters. While GBM has 11 tunable parameters, we will tune only ntrees() (number of trees) and predsamprate() (predictor sampling rate) within a small search space for simplicity. Hyperparameter tuning is an iterative procedure, and this example is only for illustration purposes.
. h2oml gbbinclass churn $predictors, h2orseed(19) cv(3, stratify)
ntrees(50(50)150) lrate(0.05) predsamprate(0.05(0.1)0.25)
tune(metric(aucpr))
Progress (%): 0 100
Gradient boosting binary classification using H2O
Response: churn
Loss: Bernoulli
Frame: Number of observations:
Training: train Training = 5,643
Cross-validation = 5,643
Cross-validation: Stratify Number of folds = 3
Tuning information for hyperparameters
Method: Cartesian
Metric: AUCPR
| Grid values | ||
| Hyperparameters | Minimum Maximum Selected | |
| Number of trees | 50 150 100 | |
| Pred. sampling rate | .05 .25 .15 | |
| Cross- | ||
| Metric | Training validation | |
| Log loss | .3531063 .4026141 | |
| Mean class error | .1784776 .2313897 | |
| AUC | .8992724 .8565935 | |
| AUCPR | .7610025 .673929 | |
| Gini coefficient | .7985448 .7131869 | |
| MSE | .1126847 .1314475 | |
| RMSE | .3356854 .3625569 | |
The header displays tuning details, including the tuning method (Cartesian), tuning metric (AUCPR), and the grid search ranges for hyperparameters. The selected values, 100 for ntrees() and 0.15 for predsamprate(), correspond to the best-performing model. The rest of the output presents the hyperparameter values and the metric summary for the optimal model.
By tuning, we increased the CV AUCPR from 0.6585 to 0.6739. The improvement is small because we explored only a small portion of the hyperparameter space in this example.
Let's store this best-tuned model for later use:
. h2omlest store gbm_tuned
We may obtain the grid-search summary by using the h2omlestat gridsummary command. This command lists the configurations of the hyperparameters we are tuning ranked by AUCPR.
. h2omlestat gridsummary Grid summary using H2O
| Pred. |
| Number of sampling |
| ID trees rate AUCPR |
| 1 100 .15 .673929 |
| 2 50 .15 .6705027 |
| 3 150 .15 .6702691 |
| 4 50 .25 .6665787 |
| 5 100 .25 .6650547 |
| 6 150 .05 .6642718 |
| 7 150 .25 .6606375 |
| 7 150 .25 .6606375 |
| 9 50 .05 .6457536 |
We may wish to compare the first two models based on other metrics by using the h2omlexplore command:
. h2omlexplore id = 1 2 Performance metric summary using H2O Training frame: train
| Model index | ||
| 1 2 | ||
| Training | ||
| No. of observations | 5,643 5,643 | |
| Log loss | .3531063 .3841674 | |
| Mean class error | .1784776 .201682 | |
| AUC | .8992724 .8845252 | |
| AUCPR | .7610025 .7304389 | |
| Gini coefficient | .7985448 .7690505 | |
| MSE | .1126847 .1220659 | |
| RMSE | .3356854 .3493793 | |
| Cross-validation | ||
| No. of observations | 5,643 5,643 | |
| Log loss | .4026141 .4111226 | |
| Mean class error | .2313897 .2234232 | |
| AUC | .8565935 .8555821 | |
| AUCPR | .673929 .6705027 | |
| Gini coefficient | .7131869 .7111641 | |
| MSE | .1314475 .1327294 | |
| RMSE | .3625569 .3643205 | |
If we choose a model other than the best-tuned one (perhaps a model with slightly worse performance but using fewer trees), we can select it via the h2omlselect command; see [H2OML] h2omlselect.
Let’s compare the best model, gbm_tuned, with the reference model from the previous section, gbm_default, based on other metrics by using the h2omlgof command.
. h2omlgof gbm_default gbm_tuned Performance metrics for model comparison using H2O Training frame: train
| gbm_def~t gbm_tuned | ||
| Training | ||
| No. of observations | 5,643 5,643 | |
| Log loss | .3293387 .3531063 | |
| Mean class error | .1592684 .1784776 | |
| AUC | .9163462 .8992724 | |
| AUCPR | .8024264 .7610025 | |
| Gini coefficient | .8326924 .7985448 | |
| MSE | .1034999 .1126847 | |
| RMSE | .321714 .3356854 | |
| Cross-validation | ||
| No. of observations | 5,643 5,643 | |
| Log loss | .411338 .4026141 | |
| Mean class error | .2338787 .2313897 | |
| AUC | .8500772 .8565935 | |
| AUCPR | .6584908 .673929 | |
| Gini coefficient | .7001545 .7131869 | |
| MSE | .1350446 .1314475 | |
| RMSE | .3674841 .3625569 | |
The output shows training results followed by CV results. Looking at the CV results, we see that tuning improved performance across all metrics: lower log loss, mean class error, MSE, and RMSE and higher AUC, AUCPR, and Gini coefficient for the tuned model indicate better model performance.
We may also refine the list of predictors based on variable importance:
. h2omlgraph varimp
;)
Based on the above graph, we may decide to drop the predictor onlinebackup.
Suppose we trained a random forest for binary classification using h2oml rfbinclass, following the same steps as before. For simplicity, suppose that after hyperparameter tuning, the best model is
. h2oml rfbinclass churn $predictors, h2orseed(19) cv(3, stratify) ntrees(200) minobsleaf(2) (output omitted) . h2omlest store rf_tuned
Now we compare the tuned random forest method (rf_tuned) with the tuned GBM method (gbm_tuned) using the test frame (the testing dataset created during the data split). We use the h2omlpostestframe command to specify the name of the frame, test in our case, to be used by all subsequent postestimation commands for computations for both the rf_tuned and gbm_tuned results:
. h2omlpostestframe test (testing frame test is now active for h2oml postestimation) . h2omlest restore gbm_tuned (results gbm_tuned are active now) . h2omlpostestframe test (testing frame test is now active for h2oml postestimation)
Instead of listing the performance metrics on the test frame separately for each method using h2omlestat metrics, we use h2omlgof to show the results side by side:
. h2omlgof rf_tuned gbm_tuned Performance metrics for model comparison using H2O Testing frame: test
| rf_tuned gbm_tuned | ||
| Testing | ||
| No. of observations | 1,400 1,400 | |
| Log loss | .4101135 .3964014 | |
| Mean class error | .2241742 .2030941 | |
| AUC | .85292 .8649185 | |
| AUCPR | .6847162 .6963289 | |
| Gini coefficient | .70584 .7298371 | |
| MSE | .1328891 .1284349 | |
| RMSE | .3645396 .3583782 | |
GBM outperforms random forest because it has a higher AUCPR, making it the preferred method. We can further compare the methods using ROC curves, where a curve closer to the upper-left corner indicates better performance. See [H2OML] h2omlgraph roc.
. h2omlgraph roc, models(gbm_tuned rf_tuned)
;)
Based on the ROC results, as we expected, the GBM method slightly outperforms the random forest method.
Another popular approach to compare classification predictions between different methods and models is by using a confusion matrix, which reports the numbers of correctly and incorrectly predicted outcomes. See [H2OML] h2omlestat confmatrix and example 4 of [H2OML] h2oml.
Suppose the company collected new data stored in newchurn.dta. It wants to predict the probability of churn for these new customers based on the GBM model gbm_tuned. Let’s read the new dataset as an H2O frame newchurn.
. webuse newchurn.dta, clear (Telco customer churn new data) . _h2oframe put, into(newchurn) replace current
We use h2omlpredict to predict churn probabilities and classes. By default, it predicts classes (Yes or No); to get probabilities, specify the pr option. In the previous section, we set test as the postestimation frame via h2omlposttestframe. To obtain predictions for the new dataset, specify frame(newchurn). Below, we predict both classes and probabilities using the GBM model gbm_tuned.
. h2omlest restore gbm_tuned (results gbm_tuned are active now) . h2omlpredict churnhat, frame(newchurn) . h2omlpredict churnprob*, frame(newchurn) pr
The generated variables for the classes (churnhat) and class probabilities (churnprob1 and churnprob2) are available in the newchurn frame because we specified frame(newchurn). Let’s list a few values for the predicted classes and probabilities.
. _h2oframe list churnhat churnprob* churnhat churnp~1 churnp~2 1 No .7780746 .2219254 2 Yes .2161581 .7838419 3 No .9001728 .0998272 4 No .8937768 .1062232 5 No .8101463 .1898537 6 Yes .2203342 .7796658 7 No .8987335 .1012665 8 Yes .4977883 .5022117 [8 rows x 3 columns]
For example, churnprob2 shows a 22% chance of churn for the first customer and 78% for the second. The predicted class (Yes or No) in churnhat is assigned based on whether churnprob2 exceeds the default F1-optimal threshold of 0.2378. This value is obtained using h2omlestat threshmetric, which displays thresholds that optimize various metrics. To use a custom threshold, specify it with the threshold() option in h2omlpredict.
One of the key challenges in machine learning is understanding why a model makes specific predictions. Explainability ensures that predictions are not only accurate but also interpretable and justifiable.
Global models describe the average behavior of a machine learning model. Examples include the following:
Local models explain individual predictions by approximating the model's behavior for a single observation. Examples include the following:
We have already seen an example of a variable importance graph; therefore, we focus on building a surrogate model here. We start by restoring the best GBM model (gbm_tuned) trained earlier.
. h2omlest restore gbm_tuned
Next we use the GBM model to predict churn for the entire dataset, rather than just the test set, by specifying the frame(churn) option:
. h2omlpredict churnhat, class frame(churn)
To improve explainability, we build a global surrogate model using, for example, a classification tree to approximate the predictions from model gbm_tuned, churnhat.
First, we switch the working frame to the full churn dataset:
. _h2oframe change churn
Then, for illustration, we train a single decision tree (ntrees(1)) with maximum depth of 3 (maxdepth(3)) as a global surrogate model:
. h2oml rfbinclass churnhat $predictors, h2orseed(19) ntrees(1) maxdepth(3) (output omitted)
This classification tree serves as a simplified approximation of the complex GBM model, making the predictions more interpretable while retaining useful insights.
A classification tree is easier to interpret visually. Using the dotsaving() option of the h2omltree command, we can generate a DOT file that can be plotted using Graphviz for better visualization; see https://graphviz.org, [H2OML] DOT extension, and [H2OML] h2omltree.
. h2omltree, dotsaving(churntree.dot, replace title(Surrogate tree for class "No"))
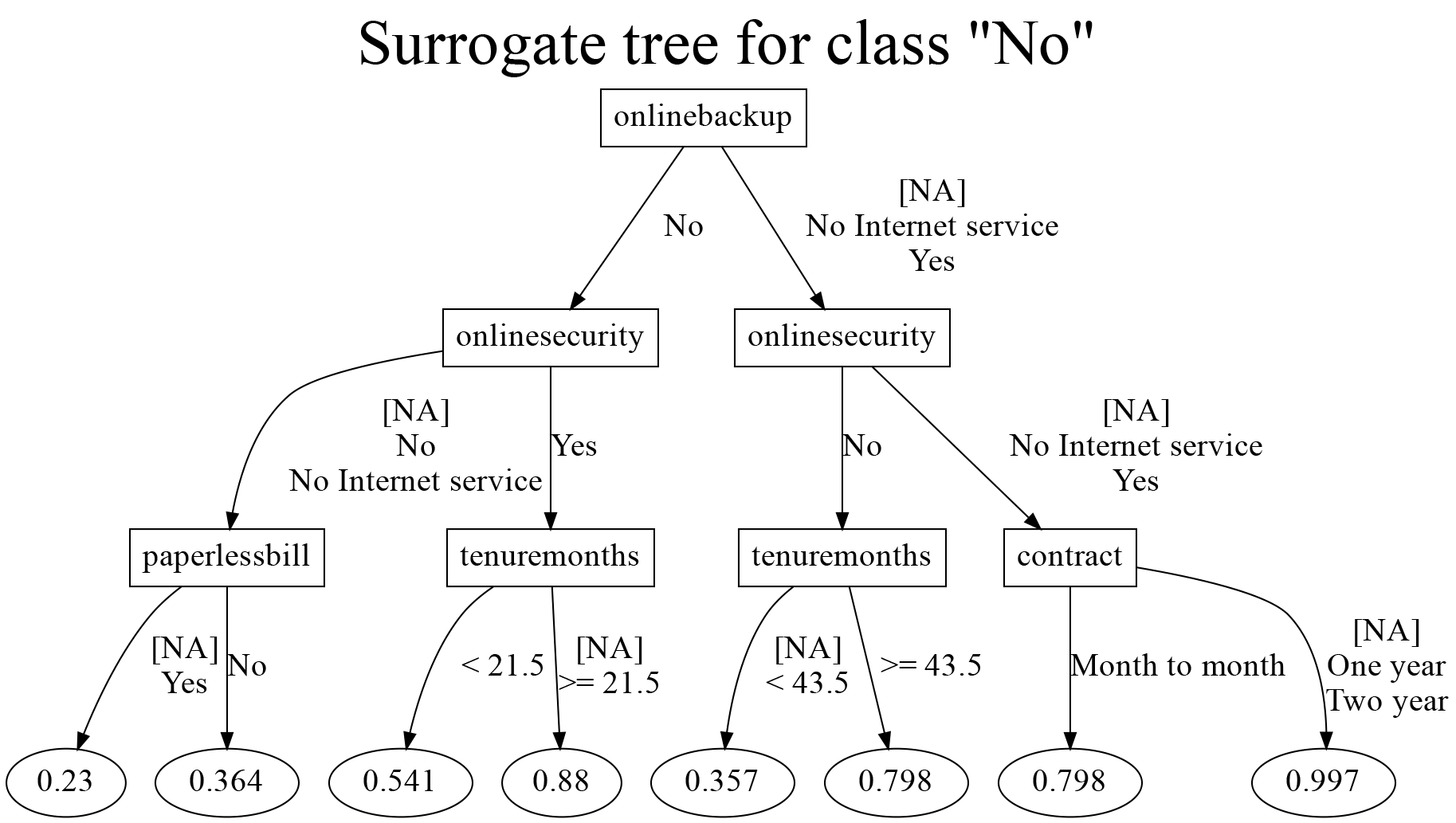
The terminal node values represent the probability of a customer not churning (No). For example, customers with one- or two-year contracts who either have no Internet service or use online backup and security have the highest probability (0.997) of staying with the company. This means their churn probability is only 0.003 (1 - 0.997), making them the least likely to leave.
Next we analyze how important predictors (identified by h2omlgraph varimp earlier) influence churn. We use PDPs, a global explainability method that shows the marginal effect of selected predictors on predictions. We first restore the GBM model's estimation results to ensure that subsequent postestimation commands apply to the best GBM model (gbm_tuned).
. h2omlest restore gbm_tuned
We use h2omlpostestframe with the notest option to set the churn dataset as the active frame for postestimation analysis without treating it as a test set.
. h2omlpostestframe churn, notest
We then generate PDPs for key predictors:
. h2omlgraph pdp contract tenuremonths onlinesecurity techsupport, combine
;)
The PDP pattern (red line in the plot) agrees with the results from the surrogate tree. For instance, the probability of churning (shown on the y axis) decreases for customers with a one- or two-year contract (contract) and for customers who use the company’s services longer (tenuremonths); see [H2OML] h2omgraph pdp.
For local explainability, we use SHAP values, which estimate each predictor’s contribution to an individual prediction. SHAP values help explain why specific customers are predicted to churn, making machine learning decisions more transparent.
We now use h2omlgraph shapvalues to produce SHAP values for observation 19 (female customer who used a month-to-month contract service for 9 months and has both the observed churn and predicted churnhat values of Yes) for the top 10 SHAP important predictors.
. h2omlgraph shapvalues, obs(19) top(10) xlabel(-2.5(0.5)2)
;)
Blue bars indicate predictors that increase churn probability, whereas red bars indicate those that reduce it. The SHAP values agree with the previous findings. Particularly, a month-to-month contract, small tenuremonths, and not using online security services contribute positively to this particular customers' churning. Note that SHAP values for binary classification are reported on the logit scale. For instance, raw prediction f(x) = 0.2063 is logit of the predicted probability that “observation 19 will churn”. You must use the inverse logit transformation to interpret them as probabilities; see [H2OML] h2omlgraph shapvalues.
The SHAP summary (beeswarm) plot visualizes SHAP values across all observations, showing both predictor importance and influence on the response. For illustration, we plot the top 4 most important predictors:
. h2omlgraph shapsummary, top(4) rseed(19)
;)
Predictors on the y axis are ranked by SHAP importance (largest absolute SHAP values first). Smaller normalized predictor values of contract (month to month versus one year versus two years), shown in blue, are associated with positive SHAP values, meaning that shorter contracts make customers more likely to leave (increase the probability of churning); see [H2OML] h2omlgraph shapsummary.
After you are done with your analysis, disconnect from the H2O cluster by using
. h2o disconnect
This closes the Stata-H2O session but keeps the cluster running in the background. You can reconnect later with
. h2o connect
To fully shut down the cluster and delete all resources, use
. h2o shutdown, force
Learn more about Stata's machine learning via H2O features.
Read more about Stata and H2O integration and about working with H2O frames.
Read more about machine learning via H2O in the Machine Learning in Stata Using H2O Reference Manual; see Tour of machine learning commands in [H2OML] h2oml.
View all the new features in Stata 18.