Notice: On April 23, 2014, Statalist moved from an email list to a forum, based at statalist.org.
[Date Prev][Date Next][Thread Prev][Thread Next][Date Index][Thread Index]
Re: st: Bug in Stata 13 (Mac) with compress duplicating variables?
From
Sergiy Radyakin <[email protected]>
To
"[email protected]" <[email protected]>
Subject
Re: st: Bug in Stata 13 (Mac) with compress duplicating variables?
Date
Sat, 3 Aug 2013 23:40:41 -0400
Wayne,
the problem you describe is then the problem of R's 'foreign' package
and not Stata's.
Indeed, Stata is known to conduct only minimal checks when loading a
file. It will tolerate many problems in the data that are not
permissible under Stata's rules. Despite loading such problematic
files without an error or a warning Stata then may break down later
on, when trying to process such data.
What you described can be reproduced with the following examples:
do http://radyakin.org/statalist/2013080301/weight.do
and
do http://radyakin.org/statalist/2013080301/wei_ht.do
These two minimal script files illustrate two problems:
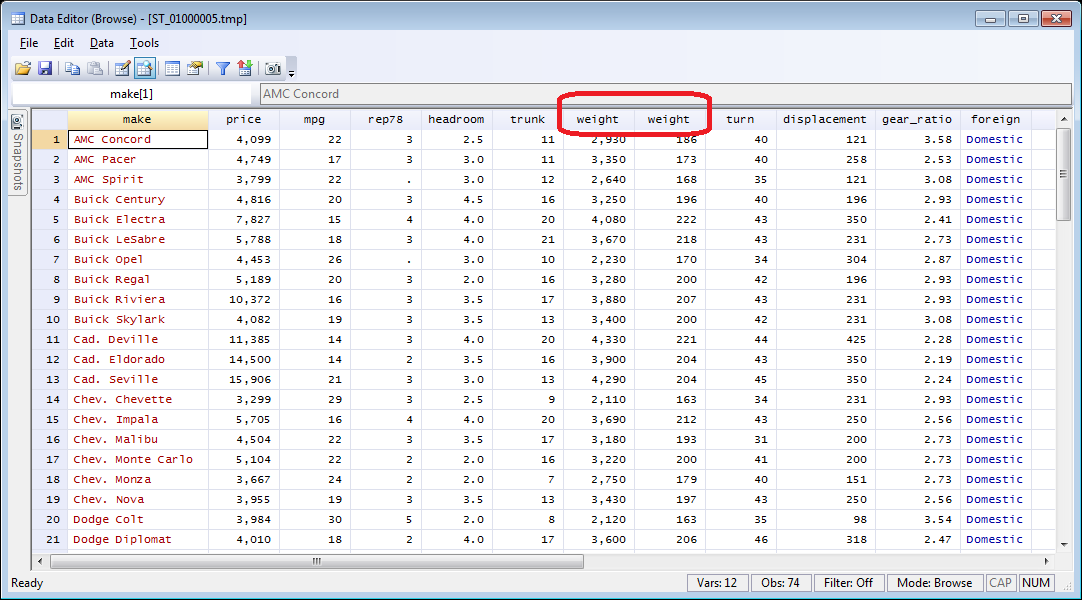
1) duplicate variable names;
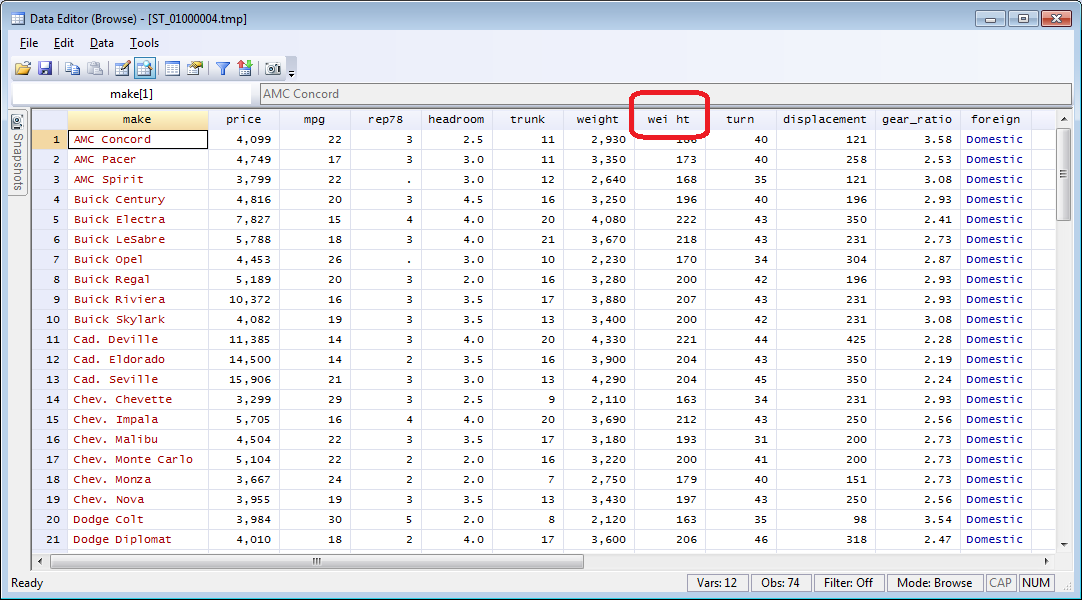
2) variable having a space in it's name.
The results are as expected:
http://radyakin.org/statalist/2013080301/weight.png
and
http://radyakin.org/statalist/2013080301/wei_ht.png
Note especially how in the second script 'describe' reports twelve
variables, and ds reports thirteen.
There are other problems that can happen during file load that deserve
a warning from Stata. I had a few experiences in my practice: one of
my programs produced variables with umlauts and other non-ASCII
characters that were opened by Stata without a warning. Not all the
commands worked with them, but most did. The response that I've got
from StataCorp on my inquiry was that the illegal characters should
not be inserted by other software as there is no support for them in
Stata and there are no guarantees for them being treated safely.
Another problem was a truncated file. A 50mb file was split to fit
1.44mb floppies, and passed to another user, which only loaded the
first part without assembling the full file first. Since the header
was present, Stata could create a 'plausible' dataset in the memory,
with much of it, of course, being filled with irrelevant content, but
if you looked at it with a 'list' command you could see some very real
numbers in the first few hundreds records, which obstructed
diagnostics. This problem has been already reported to StataCorp, and
probably already fixed by now.
Minimal checks at loading data allow Stata to achieve truly phenomenal
speeds of opening the data. It is more or less equal to the
performance of your hard drive.
If indeed the R package created erroneous content, you may want to
report the problem to the package authors. Often times presence of
small problems like this is a reflection of larger problems under the
hood, so it might be important.
R problems can be reported via:
https://bugs.r-project.org/
or by contacting the package author(s).
If your data became corrupted because of a bug like this, it is
sometimes possible to recover some or all of the data (knowing what
the bug was). So don't erase the 'broken files' before having a try,
especially if these are the only copies you've got.
Hope this helps.
Best, Sergiy Radyakin
On Sat, Aug 3, 2013 at 7:05 PM, Wayne Folta <[email protected]> wrote:
> I poked around and poked around, and I may have found something. I haven't had the chance to reproduce everything, but the dta that my data originally came from was created by exporting from R using the 'foreign' package's function to export a dta. (I have since saved over the original with saves from Stata, unfortunately, so have to recreate it.) It's possible that this introduced a problem that eventually tripped up compress.
>
> Both year and month were integers -- and not factors -- and I first though that things went wrong with compress because I remember seeing that month was compressed to a byte (makes sense, it's only 1..12), which might be coincidence or might not. I can't remember the name of the third variable, but year and month were adjacent and in the middle of the data set, column-wise, so all three might've been adjacent.
>
>
>> How about describe? ds? and what happens if you save the dataset? Are
>> there two variables with the same name that end up in the saved file?
>> Does the number of variables increase after compress? or a variable
>> got renamed incorrectly? does the problem occur only to variable year?
>> or other variables in the dataset? How is 'year' special? (e.g. this
>> is the only variable that got compressed, or the last variable, or the
>> first variable, etc).
>> Sergiy
>
>
> *
> * For searches and help try:
> * http://www.stata.com/help.cgi?search
> * http://www.stata.com/support/faqs/resources/statalist-faq/
> * http://www.ats.ucla.edu/stat/stata/
*
* For searches and help try:
* http://www.stata.com/help.cgi?search
* http://www.stata.com/support/faqs/resources/statalist-faq/
* http://www.ats.ucla.edu/stat/stata/
{kind=link}
{kind=link}